Popis aplikace

Obrázek 1: Stanovení hmotnosti brojlerů na základě plochy jejich těla v obrazu
Popis vytrénovaného modelu
Pro vytrénování modelu sloužícího ke stanovení hmotnosti zvířete byla využita architektura konvoluční neuronové sítě YOLO. V rámci trénovacího procesu bylo nutné optimalizovat hyperparametry Learning rate, Batch size a Optimizér.
Learning rate (LR) je hyperparametr optimizéru, který určuje velikost změny v každé iteraci, tj. jak rychle se posunujeme ve směru lokálního optima. Z praktického pohledu na kvalitu nalezených výsledků, příliš velké LR způsobí tzv. overfitting, tj. model se příliš rychle specializuje na nalezené lokální optimum, a nedosáhne optima globálního. Což vede v konečném důsledku k horším dosaženým výsledkům. Příliš malé LR naopak vede k velmi pomalému procesu trénování, tedy v přiděleném čase nemusí konvergovat do optima.
Batch size (BS) je velikost mini batch v každém kroku trénovaní. BS ovlivňuje trénování následujícím způsobem. Větší BS znamená vetší nároky na paměť GPU během trénování, vede k lineárnímu zrychlení trénování a dále velikost BS ovlivňuje stabilitu konvergence, a tedy nalezeného řešení.
Optimizér je z obecného pohledu postup, který říká, jak se v modelu při backpropagaci mají upravit váhy. Z praktického hlediska výběr vhodného optimizéru ovlivňuje jak kvalitu výsledného nalezeného řešení (konvergenci), tak dobu trénovaní.
Na základě porovnání vybraných metrik (Precision, Recall, mAP_0.5 a mAP_0.5:0.95) došlo k nalezení ideálních nastavení výše zmíněných hyperparametrů na hodnoty uvedené v tabulce 1.
Tabulka 1: Zjištěné optimální hodnoty hyperparametrů použitých pro vytrénování modelu
| Hyperparametr | Získaná hodnota |
|---|---|
Learning rate | 0,01 |
Batch size | 48 |
Optimizér | SGD |
Schopnost klasifikace vytrénovaného modelu je znázorněna pomocí matice záměn predikcí vyobrazené na obrázku 2. Třída chicken_full byla správně klasifikována v 99 % případů, v 11 případech byla určena jako třída chicken_part, ve 2 případech byla zaměněna za třídu chicken_active a v 6 případech nebyla modelem zaznamenána vůbec. U třídy chicken_part byla přesnost klasifikace 97 %, zaměněna byla s třídou chicken_full v 10 případech predikcí a celkem 8krát nebyla modelem detekována. Poslední třída chicken_activa byla modelem predikována s přesností 92 %, v jednom případě nebyla detekována. Z hlediska účelu využití aplikace je největším problémem záměna tříd chicken_part a chicken_activity za třídu chicken_full, u níž jako u jediné dochází k odhadování hmotnosti. K takové záměně došlo v 10 případech u třídy chicken_part.
Na obrázku 3 je představena predikce polygonálních masek sledovaných objektů vytrénovaným modelem CNN s architekturou YOLO, který je schopen identifikované obrysy klasifikovat na třídy chicken_full, chicken_part a chicken_activity.
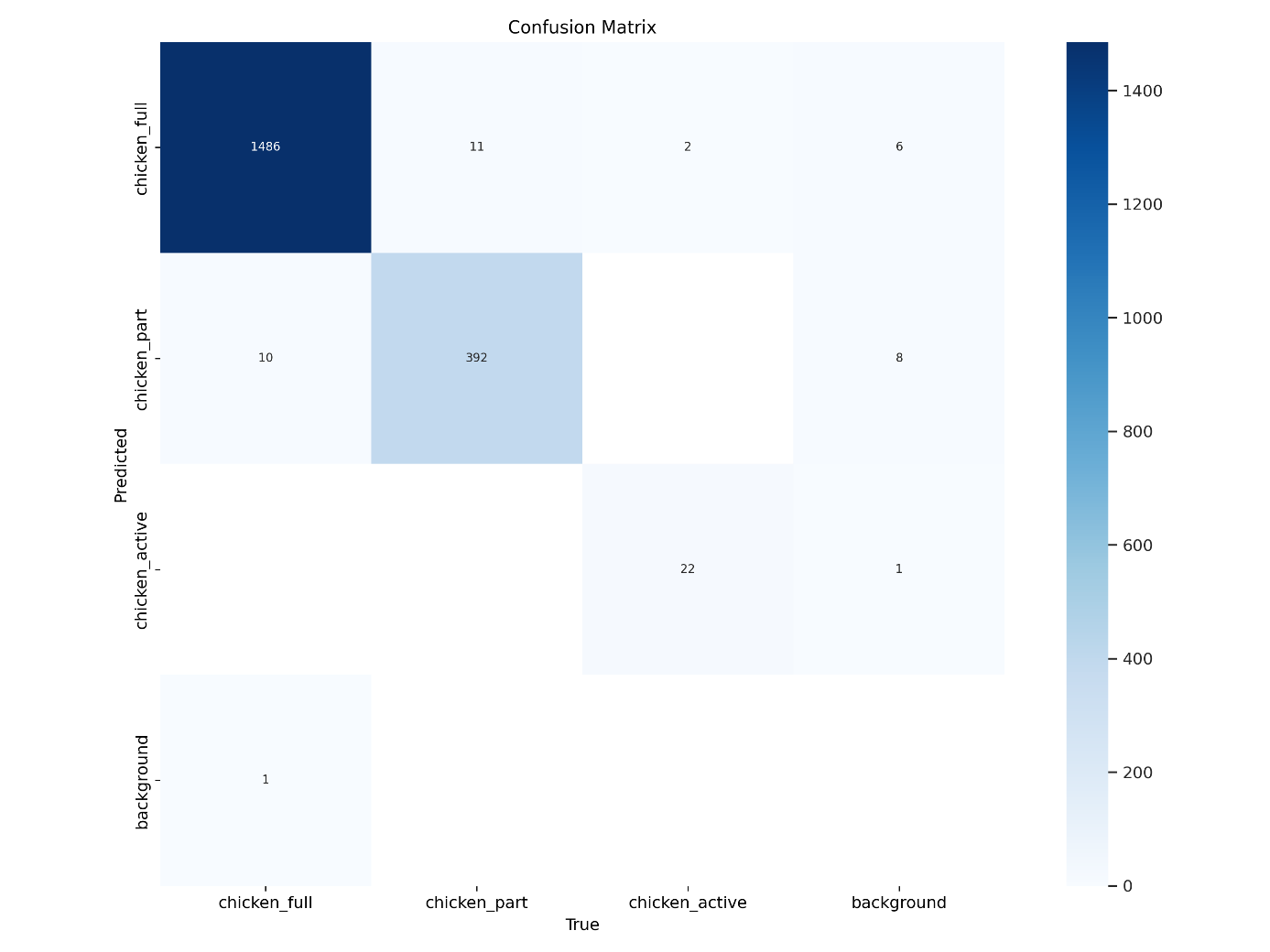
Obrázek 3: Matice záměn predikcí pro vytrénovaný model CNN s architekturou YOLO

Obrázek 3: Predikce polygonální masek sledovaných objektů vytrénovaným modelem
Popis regresní analýzy sloužící k určení vztahu mezi plochou sledovaných objektů v obraze a jejich reálnou hmotností
Po vytrénování detekčního modelu s implementovanou segmentací instancí, který umožňuje nejen jednotlivé objekty lokalizovat a určit jejich třídu, ale také přesně vymezit jejich krajní/obvodovou křivku, byly pořízené snímky spárovány s naměřenými reálnými hmotnostmi, kdy každému sledovanému kusu byla přiřazena jeho reálná hmotnost. Na základě těchto dat byla provedena regresní analýza pro zjištění vztahu mezi plochou sledovaných objektů obraze a jejich reálnou hmotností, přičemž bylo aplikováno šest regresních funkcí, viz obrázek 4, a to regrese lineární, kvadratická, polynomiální třetího řádu, polynomiální čtvrtého řádu, polynomiální pátého řádu a exponenciální, kdy se jako optimální jevila polynomiální funkce 5. řádu, která vůči datasetu vykazovala index determinace 0,97489. Rovnice této funkce dále použita pro stanovení hmotnosti jednotlivých kusů drůbeže na základě plochy jejich těla v obrazu.
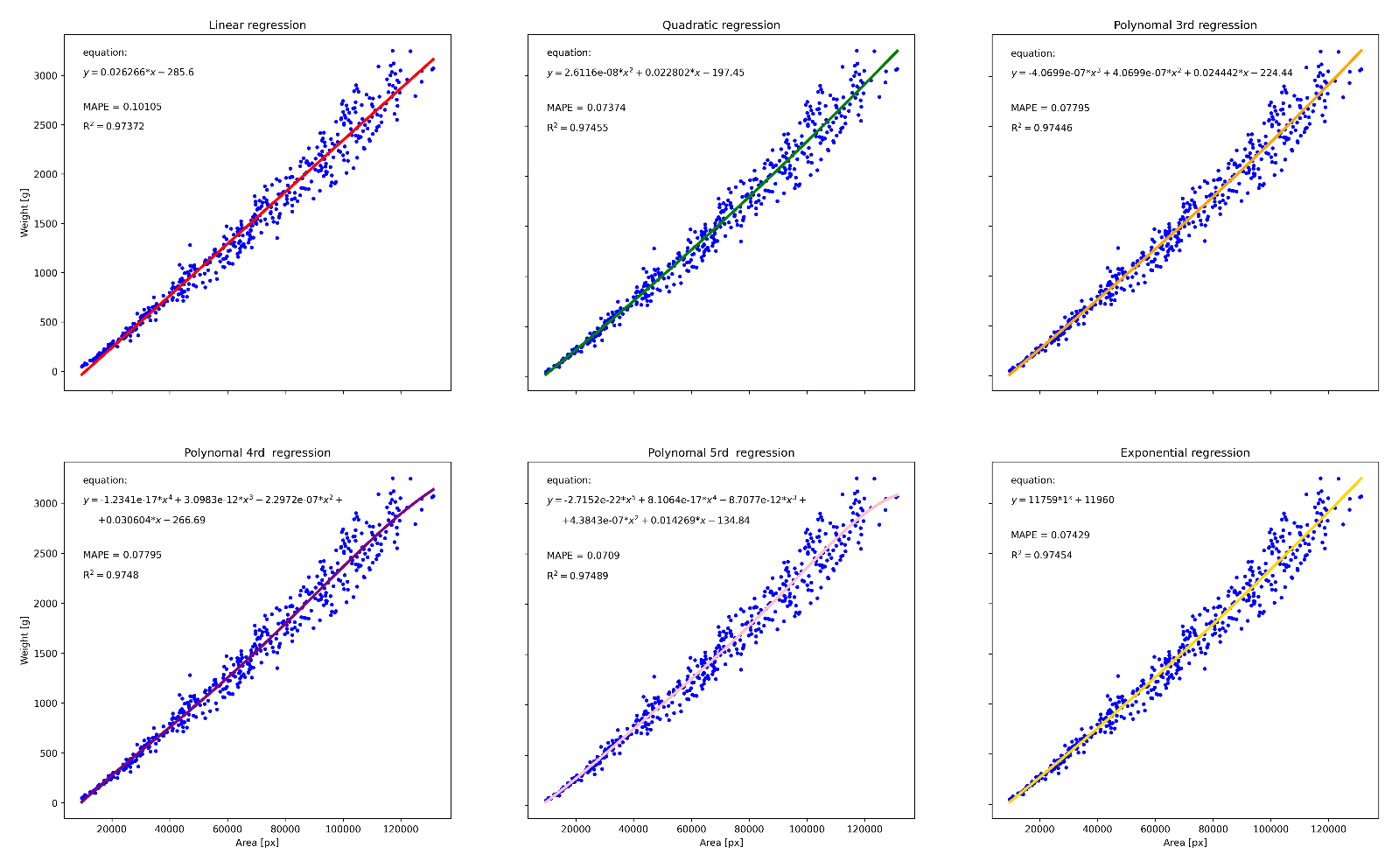
Obrázek 4: Výstupy regresní analýzy